SEO搜索引擎爬虫的工作原理(揭秘搜索引擎排名的背后)

随着互联网的发展,搜索引擎已经成为了人们获取信息的重要渠道。然而,我们是否曾想过搜索引擎是如何获取那么多的信息并进行排名呢?其背后的关键就是搜索引擎爬虫。本文将会介绍SEO搜索引擎爬虫的工作原理,以及它们如何影响搜索引擎排名。
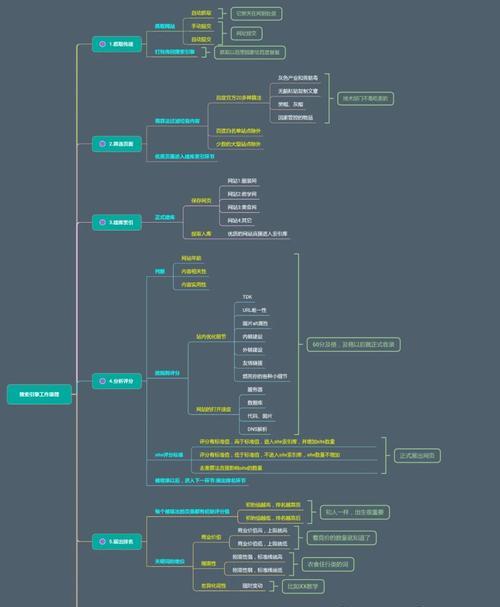
一:什么是搜索引擎爬虫?
搜索引擎爬虫是一种程序,通过自动化的方式浏览互联网,并将页面内容抓取到搜索引擎的数据库中,为用户提供检索服务。爬虫主要负责抓取和存储网页内容,帮助搜索引擎建立更完整、更准确的索引库。
二:爬虫如何工作?
当用户在搜索引擎中输入关键词进行搜索时,搜索引擎会通过自己的算法计算相关度,从数据库中找到相应的页面,并以一定的顺序呈现给用户。爬虫就是负责抓取这些页面的程序。它们按照一定的规则遍历整个互联网,将内容抓取并存储到索引库中。
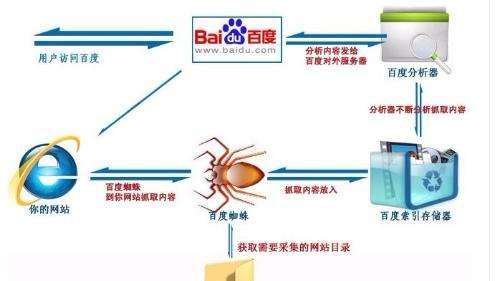
三:爬虫的爬行规则
为了更好地抓取网页,爬虫有一套自己的爬行规则。这些规则主要包括:
1、从高质量网站开始爬行,不会盲目爬行所有网站。
2、根据页面的重要性和更新频率,决定抓取的深度和频率。
3、按照页面的链接深度进行抓取,以免陷入无限循环。
四:爬虫如何判断页面价值?
为了保证用户搜索到的内容质量,搜索引擎需要对网页内容进行价值判断。爬虫就是负责进行这种判断的程序。爬虫通过判断网页的关键词密度、页面更新频率等,来决定页面的价值。同时还需要考虑用户的点击行为,以进一步确定页面的排名。
五:爬虫如何处理动态页面?
随着Web2.0时代的到来,动态页面越来越普遍。这些页面的URL是动态生成的,爬虫很难通过固定链接抓取。爬虫需要使用特殊技术来抓取动态页面。通过分析JavaScript代码来确定页面内容,或通过模拟用户操作来抓取页面。
六:爬虫如何识别重复内容?
在互联网上存在大量的重复内容,这会对搜索引擎的搜索结果造成很大的影响。爬虫通过MD5或SHA-1算法来判断内容是否重复。如果发现重复的内容,就会将其过滤掉,只保留一个版本。
七:爬虫如何处理被禁止的页面?
有些网站会使用robots.txt文件来限制爬虫的访问。当搜索引擎爬虫发现这个文件时,就会遵守其中的规则,不访问被禁止的页面。但是,有些网站不遵守这个规则,搜索引擎会对这些网站做出相应的惩罚。
八:爬虫如何处理垃圾页面?
垃圾页面是指那些仅仅为了SEO而存在的页面,它们的内容质量非常低,甚至是抄袭内容。爬虫通过算法来判断页面质量,如果发现页面质量低下,就会将其过滤掉,以保证搜索结果的质量。
九:SEO如何影响搜索引擎排名?
SEO是指通过优化网站结构、内容等来提升搜索引擎排名的一种技术。SEO可以通过一定的手段来改善网站内容质量、增加外部链接等,从而使网站被爬虫视为更高质量的页面。
十:黑帽SEO的影响
黑帽SEO是指通过欺骗手段来提升搜索引擎排名的一种非法行为。这些手段可能包括关键词堆积、隐藏文本等。这些行为会被搜索引擎爬虫识别并处以相应的惩罚,甚至导致网站从搜索结果中被移除。
十一:白帽SEO的影响
相对于黑帽SEO,白帽SEO采用的是合法、正规的技术手段。这些手段包括增加高质量外部链接、提高网站内容质量等。白帽SEO可以有效地提升搜索引擎排名,同时也不会受到搜索引擎爬虫的惩罚。
十二:SEO优化的技巧
要进行有效的SEO优化,需要掌握一定的技巧。这些技巧包括:
1、提高网站内容质量
2、增加高质量外部链接
3、使用关键词和标签
4、优化网站结构和代码
十三:SEO优化的注意事项
SEO优化虽然可以提高搜索引擎排名,但也需要注意一些事项。这些事项包括:
1、遵循搜索引擎的规则,不使用黑帽SEO技巧。
2、注重内容质量,不制造垃圾页面。
3、避免过度优化,以免被搜索引擎爬虫惩罚。
十四:SEO的未来趋势
随着人工智能技术的发展,搜索引擎将会越来越智能化。未来搜索引擎可能会通过自然语言处理等技术来理解用户需求,进一步提高搜索结果的准确度和质量。
十五:
SEO搜索引擎爬虫是现代互联网中不可或缺的一部分。了解它们的工作原理,可以帮助我们更好地理解搜索引擎排名背后的规律。同时,通过合理的SEO优化可以提高网站排名,为企业带来更多商机。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 3561739510@qq.com 举报,一经查实,本站将立刻删除。!
本文链接:https://www.jumeiyy.com/article-8862-1.html

最新文章
-

教你如何成为B站UP主实现广告分成收入
2024-12-28 -

快手的关键词:从入门到精通的SEO优化策略
2024-12-28 -

海外抖音
2024-12-28 -
B站UID是什么:深度解析与使用指南
2024-12-28 -
如何开通快手广告推广?(快手广告推广的开通流程和注意事项)
2024-12-28 -

什么是SEO?(SEO的定义及核心概念)
2024-12-28 -
百度长尾关键词排名软件:全面提升SEO效果
2024-12-28 -

快手关键词有哪些名字好听的
2024-12-28
热门文章
-

好大…用力:…深一点69,震撼全场的激情瞬间,引发热议与讨论,网友纷纷点赞!
2024-12-03 -

混乱小镇售票员如何使用B检票TxT:离谱操作直接拉满荒诞感
2024-12-03 -

“日本少萝吃大狙”现象是如何影响全球青少年消费趋势
2024-12-03 -
超级玛丽单机版攻略(游戏快乐无穷的秘籍与技巧)
2024-12-01 -

妖媚婷儿户外勾引,惊现撩人瞬间,引发众人围观热议!
2024-12-01 -

B站视频推广:视频标题优化技巧
2024-12-05 -

B站视频推广:玩转B站营销!品牌投放推广5个核心策略
2024-12-08 -

如何在DNF游戏中获取更多的魔法石(掌握这些技巧)
2024-12-04