B站关键词视频信息爬虫:全面解析与实现步骤

在内容为王的互联网时代,如何快速准确地获取特定关键词下的视频信息成为了许多内容创作者、市场研究者和数据分析师的需求。而借助B站关键词视频信息爬虫技术,我们能够高效地实现这一目标。本文将全面解析B站关键词视频信息爬虫的实现步骤,帮助您轻松掌握这一技术。
爬虫,也就是网络机器人,是一种按照特定规则,自动抓取互联网信息的程序或脚本。它能够帮助我们从海量的数据中筛选、整理出有价值的信息。
作为国内知名的视频分享平台,B站(哔哩哔哩)拥有大量的用户生成内容,但其数据通常受版权保护,直接爬取可能存在法律风险。在进行B站爬取之前,我们应确保遵守相关法律法规,尊重版权,并尽可能减少对平台服务器的影响。

二、准备工作:了解B站API和爬虫框架
在实际动手编写爬虫之前,对B站的API进行了解是必不可少的。B站提供了API,允许开发者以编程方式访问其平台的一些信息。选择合适的爬虫框架,如Python中的Scrapy、BeautifulSoup等,能够大幅提高开发效率。
1.B站官方API
B站提供了官方API,对于合法使用场景下,我们可以通过API获取许多公开数据,例如视频信息、用户信息等。记住,在使用之前要仔细阅读官方文档,了解使用限制和认证机制。
2.选择爬虫框架
Python被广泛用于爬虫开发,它不仅有丰富的库支持,还有成熟的框架。选择合适的框架能够帮助我们更高效、更有组织地编写爬虫代码。Scrapy是一个快速高层次的网页爬取和网页爬取框架,适合大规模数据抓取。
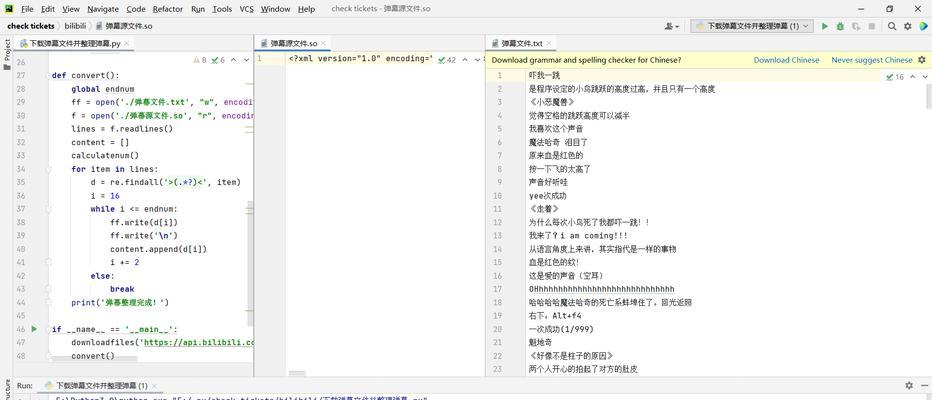
三、爬虫编写步骤详解
1.环境准备
确保您的开发环境已安装Python,并安装了爬虫框架和其他必要的库,如requests,用于网络请求;json,用于处理JSON数据;以及可能需要的其他库。
2.发起请求与解析数据
使用爬虫框架或者直接编写脚本发起网络请求,获取B站搜索关键词后的页面源码。然后解析页面,提取出视频的相关信息,如标题、播放量、弹幕数量、评论数等等。
3.存储数据
获取到的数据需要存储起来,便于后续分析。可以存储在CSV文件、数据库,或者其他的存储系统中。
4.异常处理和日志记录
爬虫在运行过程中可能会遇到各种异常情况,如网络请求失败、解析错误等,因此编写异常处理代码和日志记录是必要的,它可以帮助我们追踪问题并优化爬虫。
5.尊重robots协议
robots.txt是网站中告诉爬虫哪些页面可以抓取,哪些不可以的小文件。在编写爬虫时,应遵守目标网站的robots.txt协议,以示尊重。

四、B站关键词视频信息爬虫实战演练
1.使用B站API获取关键词视频列表
以合法方式使用B站API,根据提供的关键词搜索视频,并获取返回的JSON数据。
示例代码(使用requests库):
```python
importrequests
importjson
假设您已经获取到了B站API的key和accesstoken等认证信息
headers={
'User-Agent':'YourUserAgent',
'Authorization':'BearerYOUR_ACCESS_TOKEN',
根据需要添加其他headers
params={
'bvid':'',空白表示搜索全局
'keyword':'您的关键词'替换为您想搜索的关键词
response=requests.get('https://api.bilibili.com/x/web-interface/search/type',headers=headers,params=params)
data=response.json()
print(json.dumps(data,indent=2,ensure_ascii=False))
```
2.解析返回的JSON数据
从返回的JSON数据中提取您所需要的信息,如视频标题、作者等。
示例代码:
```python
ifdata['code']==0:确保请求成功
foritemindata['data']['items']:
title=item['title']视频标题
author=item['owner']['name']视频作者
print(f"视频标题:{title},作者:{author}")
```
3.注意事项
确保您的爬虫有适当的延时机制,以避免对B站服务器造成不必要的负担。
如果您计划抓取大量数据,可以考虑使用B站提供的付费数据服务,以合法、稳定的方式获取数据。
五、与未来展望
通过本篇指南,您已经了解了B站关键词视频信息爬虫的全貌。从理论知识到实践操作,每一个步骤都需要仔细研究和实践。随着技术不断进步,未来的爬虫可能更加智能,能够处理更加复杂的任务,同时我们也要持续关注相关法律法规的更新以确保合规使用。
B站作为重要的视频内容平台,其数据对于研究和分析有着不可忽视的价值。掌握了爬虫技术,就如同开启了探索宝藏的钥匙。但请记住,使用时必须遵守法律法规,尊重版权和隐私,合理使用数据资源。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 3561739510@qq.com 举报,一经查实,本站将立刻删除。!
本文链接:https://www.jumeiyy.com/article-6290-1.html








最新文章
-

梦幻西游三傻退游后如何处理?
2025-04-03 -

生存工具任务在魔兽世界中怎么做?完成任务的步骤是什么?
2025-04-03 -

魔兽世界怎么更改PVE模式?更改模式的步骤是什么?
2025-04-03 -
花海国服李白账号售价是多少?
2025-04-03 -

手游中单挑派克应该出什么装备?
2025-04-03 -
王者荣耀祈愿抽奖技巧是什么?
2025-04-03 -

洛克王国中红桃雀后装扮的获取方式是什么?
2025-04-03 -

大话手游内丹系统在哪个区开放?如何参与?
2025-04-03
热门文章
-
王者荣耀隐私设置在哪里?如何保护个人信息?
2025-03-15 -

洛克王国先锋军主培养技巧有哪些?如何有效提升实力?
2025-03-10 -

我的世界中汤的制作方法是什么?有哪些汤类食谱?
2025-03-06 -

原神中冒充雷神的触发条件是什么?
2025-03-11 -

东京主题手游有哪些推荐?最佳东京风格游戏是什么?
2025-03-11 -

最火最仙的手游是哪个游戏?如何选择适合自己的仙侠手游?
2025-03-08 -
王者荣耀随机王者英雄怎么设置?如何设置随机英雄?
2025-03-08 -

王者荣耀皮肤获取途径?如何快速获得心仪的皮肤?
2025-03-15