知乎关键词搜索爬虫怎么用?常见问题有哪些?

知乎关键词搜索爬虫全面解析
在大数据时代,信息检索与处理的重要性不言而喻。对于内容创作者、市场分析师和数据科学家而言,能够从海量的信息中快速提取出有价值的数据尤为重要。知乎,作为中国领先的问答社区平台,其内容的深度和广度吸引了众多用户的积极参与,掌握知乎关键词搜索爬虫技术,意味着能够高效捕获知乎上用户关注的话题和数据,为个人或企业的决策提供信息支持。本文将全面解析知乎关键词搜索爬虫的实现思路和操作步骤,帮助读者深入理解和掌握这一技能。

什么是知乎关键词搜索爬虫?
知乎关键词搜索爬虫,简单来说,就是一种能够模仿用户在知乎平台进行关键词检索,并从大量的搜索结果中提取相关数据的自动化脚本。这种爬虫通常利用知乎的搜索接口,通过编程实现对指定关键词信息的抓取,进而分析和处理这些数据。
知乎关键词搜索爬虫的法律和道德边界
在开始构建爬虫之前,我们必须明确法律法规对于爬虫行为的限制。在中国,《网络安全法》明确指出,网络运营者收集和使用个人信息必须遵循合法、正当、必要的原则,未经用户同意,不得收集用户个人信息。对于爬虫行为,也应遵守网站的Robots协议,尊重网站设置的爬虫访问权限。在构建和使用知乎关键词搜索爬虫时,必须确保其不侵犯用户隐私,不违反相关法律法规。

构建知乎关键词搜索爬虫的基本步骤
1.确定目标关键词
你需要明确自己希望通过爬虫获得什么样的数据。这需要你对目标关键词进行充分的分析,理解这些关键词在网络中的热度、相关性以及它们与业务目标之间的关联。
2.分析知乎搜索结果页面的结构
接下来,通过浏览器的开发者工具(如Chrome的F12工具),来分析知乎搜索界面的HTML结构,找到包含搜索结果的标签和类名,这是编写爬虫代码抓取数据的关键。
3.编写爬虫代码
在确定了目标关键词和页面结构之后,我们可以使用如Python中的requests库来获取网页内容,然后通过BeautifulSoup来解析HTML并提取数据。
4.数据存储与分析
提取的数据通常需要存储在数据库中,如MySQL或MongoDB等。之后,可通过各种数据分析工具或自编脚本对数据进行进一步的分析处理。
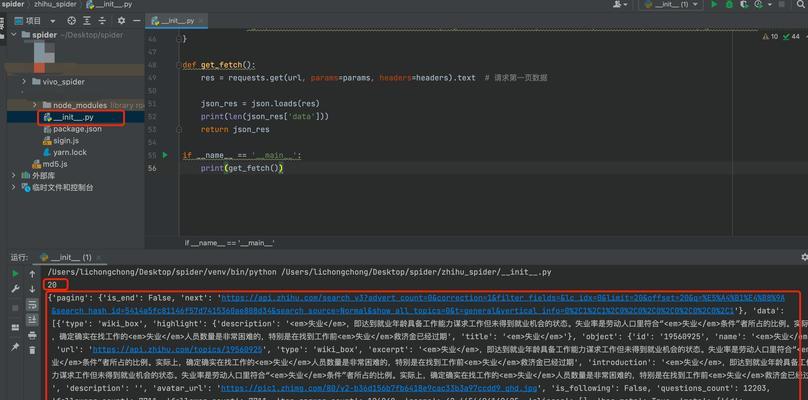
一个简单的知乎关键词搜索爬虫实战案例
假设我们需要统计某一关键词在知乎上的热度,我们可以使用以下Python代码进行实现:
```python
importrequests
frombs4importBeautifulSoup
设置关键词
keyword='Python编程'
首页URL
url='https://www.zhihu.com/search'
构造搜索参数
payload={'keyword':keyword}
发送请求获取响应
response=requests.get(url,params=payload)
确认请求成功
ifresponse.status_code==200:
解析HTML
soup=BeautifulSoup(response.text,'html.parser')
根据页面结构定位搜索结果
results=soup.find_all('div',class_='Card-list')
输出结果
print(f"找到{len(results)}条关于'{keyword}'的问题。")
else:
print("请求失败,请检查网络连接或关键词设置。")
```
常见问题与技巧
Q1:如何防止爬虫被知乎封禁?
A1:合理控制爬取频率,遵守知乎的Robots协议,并为爬虫增加合适的User-Agent,这是避免爬虫被封禁的基本措施。
Q2:爬虫可以提取哪些数据?
A2:理论上,爬虫可以提取知乎平台上公开可见的任何数据,包括问题、答案、用户信息等。但务必注意数据使用范围,避免侵犯用户隐私。
Q3:如何处理大量的搜索结果?
A3:可以使用分页技术,即在爬虫代码中加入对分页的处理逻辑,结合数据库分批存储数据,提高数据处理的效率。
结语
通过以上步骤,你应能构建起自己的知乎关键词搜索爬虫,并开始进行数据的提取与分析。本文旨在为读者提供一个全面的指导,从理论到实践,从技术到法律,处处都为读者的实际操作考虑,确保读者能够在保证合法合规的前提下,享受数据带来的无限可能。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 3561739510@qq.com 举报,一经查实,本站将立刻删除。!
本文链接:https://www.jumeiyy.com/article-22503-1.html






最新文章
-

全网最好的小精灵手游推荐?小精灵手游有哪些特点?
2025-03-31 -

红警巨炮怎么快打?提高巨炮攻击速度的技巧有哪些?
2025-03-31 -
王者荣耀中哪个学院是下路的?
2025-03-31 -

三国杀中欣儿角色现状如何?欣儿最近有什么变化?
2025-03-31 -
危险世界中队友传送方法是什么?操作步骤详细吗?
2025-03-31 -

梦幻西游飞升化圣登神需要多少费用?具体价格是多少?
2025-03-31 -

如何在魔兽世界中接取缅怀英雄任务?
2025-03-31 -

梦幻西游蝴蝶泉4进2比赛结果如何?
2025-03-31
热门文章
-
王者荣耀隐私设置在哪里?如何保护个人信息?
2025-03-15 -

洛克王国先锋军主培养技巧有哪些?如何有效提升实力?
2025-03-10 -

我的世界中汤的制作方法是什么?有哪些汤类食谱?
2025-03-06 -
魔兽世界71术士改动详情(一文详解术士最新变动)
2025-03-02 -

原神中冒充雷神的触发条件是什么?
2025-03-11 -
魔兽世界71强势职业一览(详细解析魔兽世界中的71个强势职业)
2025-03-02 -

东京主题手游有哪些推荐?最佳东京风格游戏是什么?
2025-03-11 -

最火最仙的手游是哪个游戏?如何选择适合自己的仙侠手游?
2025-03-08