分布式搜索引擎的工作原理及其优势

搜索引擎作为互联网信息获取的重要入口,对于大数据时代的我们来说,其作用不言而喻。随着信息量的激增,传统搜索引擎的信息处理能力开始面临挑战。在这种背景下,分布式搜索引擎应运而生,它通过分布式计算方式突破了传统搜索引擎的瓶颈,实现了高效率和高可扩展性的信息检索。分布式搜索引擎是如何工作的呢?它又具备哪些独特的优势呢?接下来,让我们深入探讨分布式搜索引擎的奥秘。
分布式搜索引擎的工作原理
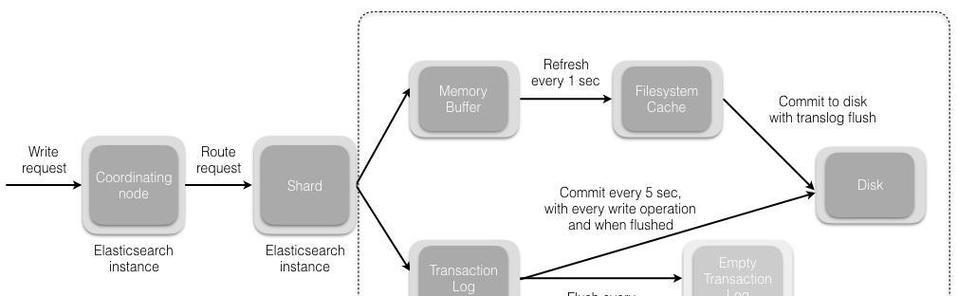
1.数据分布式存储
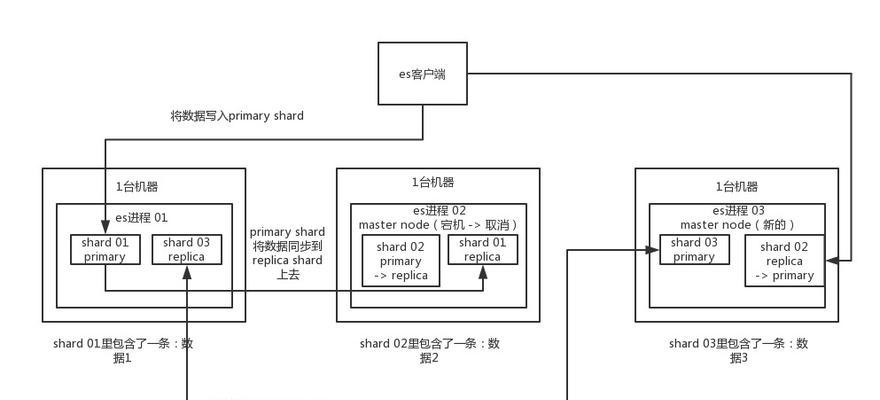
分布式搜索引擎首先会将大数据分散存储在多个服务器上,每一个服务器被称作一个节点。因为数据被分布存储,所以任何一个节点的失败都不会导致整个系统的崩溃。每个节点存储一部分数据,这使得搜索引擎能够有效地利用多台计算机的计算和存储资源来处理数据。
2.数据的索引与分片
在分布式系统中,数据被索引化并分成多个分片。这些分片分布在不同的节点上,使得整个系统能够并行处理大量的数据。索引的创建是为了快速定位和检索数据,分片则有助于实现负载均衡,提升数据处理的效率。
3.分布式计算与查询处理
当用户发起查询请求时,分布式搜索引擎会根据查询语句的不同要求,将任务下发至多个节点,由这些节点并行处理。查询处理完成后,各个节点会汇果,并对结果进行合并排序,最后返回给用户。
4.整合与优化
分布式搜索引擎融合了多种技术,如数据分片技术、负载均衡、容错机制、一致性算法等,以确保系统的稳定性和可靠性。为了进一步优化性能,系统还会进行实时或定期的数据迁移和重新分配。
分布式搜索引擎的优势
1.高可扩展性
分布式搜索引擎由于具备水平扩展能力,所以能够轻松应对数据量的不断增长。通过添加更多的节点,系统可以提升其整体处理信息的能力,满足大规模数据处理的需求。
2.高容错性
在分布式系统中,数据通常会有多个副本,分布在不同的节点上。即使某个节点发生故障,系统仍可以从其他节点获取数据,因此具有很强的容错能力。
3.高效率
分布式搜索引擎通过并行处理数据,大幅提升了数据的处理速度。这意味着用户在查询时可以获得更快的响应时间,特别是在处理海量数据时,相较于传统搜索引擎优势更为明显。
4.成本效益
由于分布式搜索引擎能够有效利用廉价的商用硬件构建,相比依赖昂贵的大型机或专用服务器硬件的传统搜索引擎而言,具有更高的成本效益。
5.强大的容错和恢复能力
在分布式搜索引擎的多个节点中,任何节点出现故障都不会影响整个系统的运行。系统可以自动检测并恢复故障节点,确保数据不丢失且能够快速恢复服务。
综上所述,分布式搜索引擎通过分布式存储、索引分片、并行计算等技术手段实现了对海量数据的高效处理。它不仅具有强大的可扩展性和容错能力,还能够为用户提供更快、更稳定的搜索体验。随着技术的不断进步,分布式搜索引擎将在处理大数据和提供更智能化的信息检索服务中发挥越来越重要的作用。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 3561739510@qq.com 举报,一经查实,本站将立刻删除。!
本文链接:https://www.jumeiyy.com/article-14845-1.html
最新文章
-

魔兽戒指任务完成方法是什么?任务流程详细解析?
2025-04-17 -

英雄联盟运行需要的最低电脑配置是什么?
2025-04-17 -

英雄联盟中皇子的父亲是谁?他的名字是什么?
2025-04-17 -

王者荣耀中关闭精准攻击的步骤是什么?
2025-04-17 -

魔兽世界材料转移失败原因是什么?
2025-04-17 -

上古魔兽黑龙快速打法是什么?
2025-04-17 -

英雄联盟狮子狗打野推荐出装是什么?如何选择装备?
2025-04-17 -

王者荣耀实名认证失败后如何重新进行实名?
2025-04-17
热门文章
-

王者荣耀头像更换步骤是什么?自定义头像有哪些限制?
2025-03-19 -
王者荣耀中嘎雅的正确路线是什么?如何快速到达?
2025-04-13 -
王者荣耀反甲如何破解?面对反甲英雄的策略是什么?
2025-03-31 -

英雄联盟变紫色怎么办?游戏界面变色的原因及解决方法?
2025-04-13 -

魔兽世界中代码是如何使用的?
2025-04-14 -

魔兽世界中徐弥陀的打法是什么?有哪些策略可以采用?
2025-04-13 -
绝地求生压枪技巧有哪些?如何精准调节?
2025-04-03 -

迷你世界更新方法是什么?
2025-03-29