分布式搜索引擎:定义、原理、优势与应用

在大数据时代,人们对信息检索的效率和准确性提出了更高的要求。分布式搜索引擎应运而生,它突破了传统搜索引擎的局限,以高效、可扩展、容错性强的特点,满足了现代社会对信息检索的需求。本文将为您全面解析分布式搜索引擎的定义、工作原理、优势以及其在各领域的应用。
一、分布式搜索引擎的定义
分布式搜索引擎是一种基于分布式计算架构设计的搜索引擎,它通过分布在网络上的多个节点协同工作,实现对大量数据的快速索引和检索。这种搜索引擎可以有效地处理PB级别的数据量,广泛应用于互联网搜索、大数据分析和企业级搜索解决方案中。
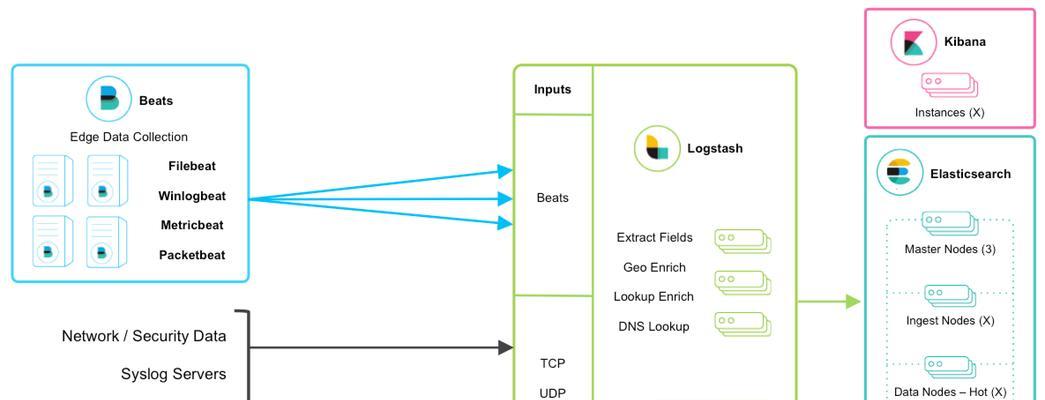
二、分布式搜索引擎的原理
2.1数据分片与索引
分布式搜索引擎首先需要将存储的数据进行分片,然后在不同的节点上进行索引。每个节点只负责一部分数据的索引工作,这样不仅提高了数据处理的效率,也降低了单点故障的风险。
2.2查询处理与结果聚合
当用户提出查询请求时,分布式搜索引擎会将查询发送到所有节点,各节点并行处理查询并返回结果。最后由中心节点对所有节点返回的结果进行综合排序和聚合,向用户提供最终的搜索结果。
2.3分布式计算与存储
为了保证系统的可扩展性和容错性,分布式搜索引擎采用了分布式计算与存储技术。这种技术允许系统动态增加或减少节点,同时保持系统的稳定运行。

三、分布式搜索引擎的优势
3.1高效的数据处理能力
分布式搜索引擎能够处理比传统搜索引擎更多的数据,并且响应时间更短,为用户提供更好的搜索体验。
3.2良好的可扩展性
通过增加或减少节点数量,分布式搜索引擎可以轻松地扩展或缩减其处理能力,满足业务随时间增长的需求。
3.3强大的容错和恢复能力
分布式搜索引擎通过数据冗余存储和快速的故障检测机制,保证了系统在面对节点故障时的稳定运行。
四、分布式搜索引擎的应用
4.1互联网搜索引擎
谷歌、百度等大型互联网公司使用分布式搜索引擎为全球用户提供快速准确的搜索服务。
4.2大数据分析平台
分布式搜索引擎在大数据分析平台上得到了广泛应用,帮助企业和研究机构高效管理和分析大量的数据集。
4.3企业内部搜索解决方案
许多大型企业利用分布式搜索引擎构建企业级的搜索解决方案,以提升内部文档和数据的检索效率。
五、深度指导:如何构建一个基本的分布式搜索引擎
5.1确定搜索引擎的需求与架构
在构建分布式搜索引擎之前,首先需要明确搜索需求和预期的系统架构。这包括数据量大小、查询频率、预算限制等因素。
5.2选择合适的技术堆栈
选择合适的技术堆栈是构建分布式搜索引擎的关键一步。一些流行的技术组件包括Elasticsearch、Hadoop、ApacheSolr等。
5.3设计数据索引和查询处理机制
设计高效的数据索引和查询处理机制至关重要。这涉及到数据分片策略、负载均衡、查询优化等技术细节。
5.4测试与优化
系统构建完成后,进行严格的测试和性能优化是必不可少的。这包括了功能测试、性能测试和故障恢复测试等。
六、常见问题解答
6.1分布式搜索引擎与传统搜索引擎有何区别?
分布式搜索引擎相较于传统搜索引擎,主要区别在于其可以通过增加节点来水平扩展,同时具备更高的容错性和可靠性。
6.2如何选择合适的分布式搜索引擎技术?
根据实际需求和应用场景选择合适的分布式搜索引擎技术至关重要。对于高并发和大数据量处理,Elasticsearch是一个不错的选择;而对于需要处理大规模批量数据的场景,Hadoop更合适。
6.3分布式搜索引擎的主要挑战是什么?
分布式搜索引擎主要面临的挑战包括数据一致性、负载均衡、扩容维护和安全性问题。
七、结语
分布式搜索引擎以其强大的数据处理能力和高度的可扩展性,正在成为搜索引擎领域的重要力量。随着技术的不断进步和应用场景的扩展,分布式搜索引擎将更好地满足人们对于信息检索的需求。通过本文的介绍,希望读者对分布式搜索引擎有了全面的了解,并能够在实际应用中发挥其优势。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 3561739510@qq.com 举报,一经查实,本站将立刻删除。!
本文链接:https://www.jumeiyy.com/article-11432-1.html




最新文章
-

魔兽戒指任务完成方法是什么?任务流程详细解析?
2025-04-17 -

英雄联盟运行需要的最低电脑配置是什么?
2025-04-17 -

英雄联盟中皇子的父亲是谁?他的名字是什么?
2025-04-17 -

王者荣耀中关闭精准攻击的步骤是什么?
2025-04-17 -

魔兽世界材料转移失败原因是什么?
2025-04-17 -

上古魔兽黑龙快速打法是什么?
2025-04-17 -

英雄联盟狮子狗打野推荐出装是什么?如何选择装备?
2025-04-17 -

王者荣耀实名认证失败后如何重新进行实名?
2025-04-17
热门文章
-

王者荣耀头像更换步骤是什么?自定义头像有哪些限制?
2025-03-19 -
王者荣耀中嘎雅的正确路线是什么?如何快速到达?
2025-04-13 -
王者荣耀反甲如何破解?面对反甲英雄的策略是什么?
2025-03-31 -

英雄联盟变紫色怎么办?游戏界面变色的原因及解决方法?
2025-04-13 -

魔兽世界中代码是如何使用的?
2025-04-14 -

魔兽世界中徐弥陀的打法是什么?有哪些策略可以采用?
2025-04-13 -
绝地求生压枪技巧有哪些?如何精准调节?
2025-04-03 -

迷你世界更新方法是什么?
2025-03-29